Building CreateTable.io
While contracting for the last couple years with a number of companies I’ve run into some recurring data ingestion problems. One of those is loading data from many sources, often customers, into a single unified schema. This process is often manual and error prone. It lacks good tooling to automate the process, review validation errors, and often leads to issues in downstream processes that rely on the data.
To make this process easier and more reliable, I’ve built CreateTable.io. But first, here’s some of what its trying to solve a bit on how its built.
Core Issues
1. Data Mapping
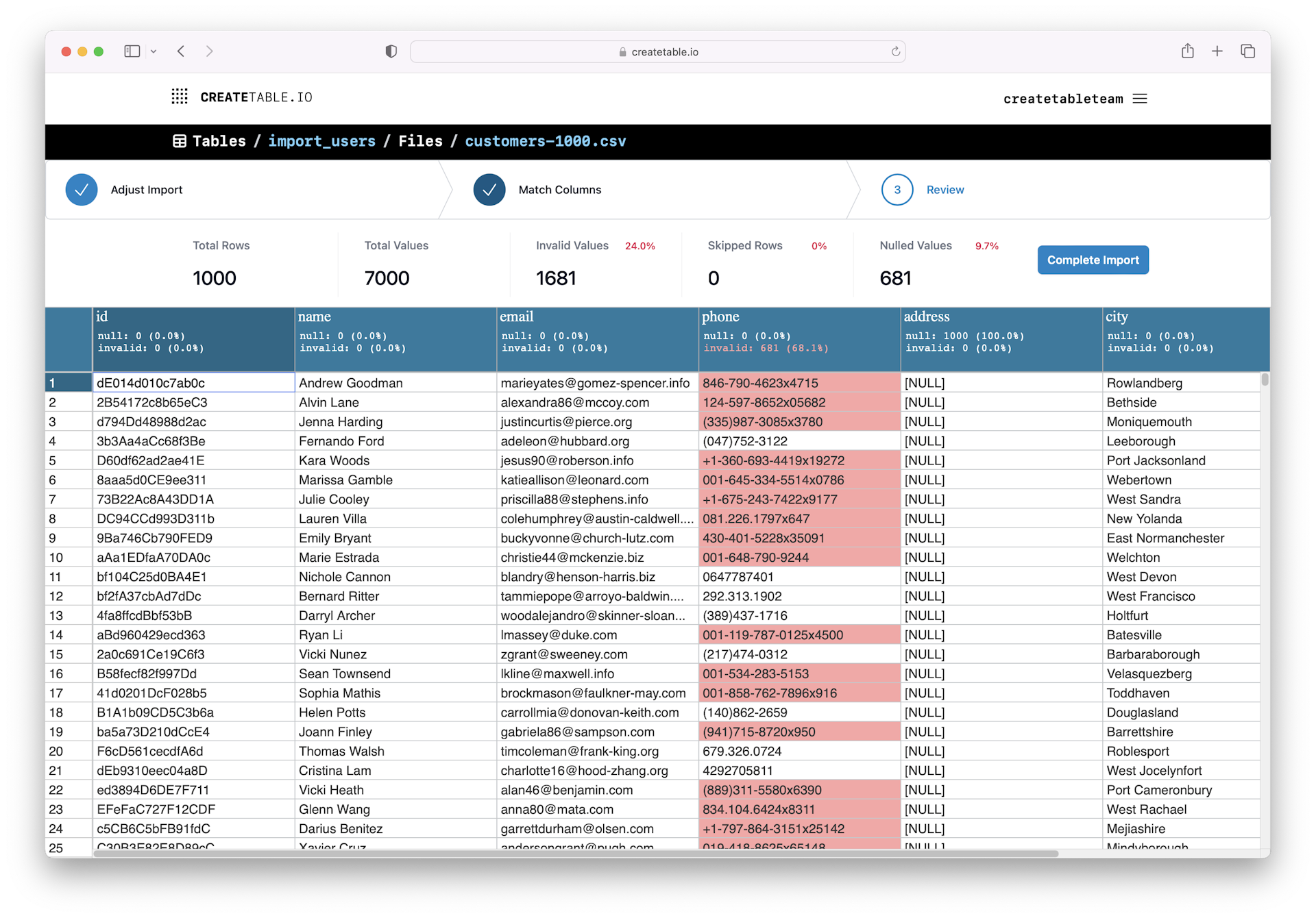
Start of the process is trying to match or map the input columns to the final schema. This is often not a 1:1 mapping and requires transformations. This process is repetitive and and easily prone to error.
2. Validation
Even with column names are matched, does the meaning of the data match? is the data formatted in expected ways? Is the data being load even consistent in format? Most of the time, the answer is no, no, no.
Depending on the data validation needs to strictly reject any bad input data, other dataset maybe skipping a few errors is acceptable.
3. Workflow and Collaboration
The process of mapping and validation is often a team effort. Multiple people should be able to step in to parts of the process. The workflow should be easy to start, stop, and pick up where you left off. I saw teams loading 100s or 1000s of files and tracking the progress in a spreadsheet between people involved in acquiring the files and those loading the data.
Other Goals
1. Self Host or SaaS
Especially in the data space, there are many reasons to want to self host. Data privacy, security, and compliance are all reasons to want to self host or run “on-prem”. The Saas service would be easier for a lot of users, but should have the option to self host from the start.
2. Minimal Service Dependencies
As something that is intended to be self hosted, it should have the fewest dependencies possible on external services. It should be able to run on a cloud VM, a bare metal server, or even a laptop. The only expected service currently is an email provider for sending login links and other notifications.
Using CreateTable
CreateTable is built as a web application, centered around teams. Users of those teams can create new table schemas or use existing ones from their team, and upload files that target the desired schema and validations. Each file is processed individually. The file is loaded, and the columns are matched to the target schema. There is automatic matching (how that works is discussed below), but the user reviews and can manually override the matches as needed. After the columns are matched, validations are run over the whole dataset, and the results including a preview of any invalid data is shown to the user. The user can finalize the import, reject it, or make changes in the matching to fix the validation errors.
Once files have been imported to the target schema, those file can be exported in a number of formats individually or combined as a single file and then loaded into a data warehouse, or used in other processes.
Tech Stack
Golang
No surprises here, just a solid language with good libraries for building web services. There are other reasonable choices, but Go is a good fit. Also the ease of distributing a single binary per platform with all the assets included is a big win for self hosting.
SQLite
SQLite as a default makes the self hosting quick and easy to get started. SQLite is used for the configuration, users management, and file metadata. The Saas version uses SQLite on replicated block storage for high availability and durability. It keeps separate databases per each team account, which make the option of moving from Saas to self hosted very easy.
DuckDB
The superpower behind CreateTable is DuckDB. DuckDB is an in-process columnar OLAP query engine. The data processing steps start with loading data via DuckDB then doing all the transformations, column stats, and validations as SQL queries.
MPA (Multi Page Application)
Not a specific tech, but a design choice. The application has separate server side templates for each page. These are then enhanced with client side interactivity as needed. There is still shared code between the pages, but each page has a limited scope to the interactions and state it needs to manage. And its fast to load and render.
Alpine.js
For the client side interactivity, since it is limited in scope to a single page, Alpine.js has been solid choice. There are some templated components that are shared across pages and Alpine.js has been a good fit for that as well.
TailwindCSS
TailwindCSS both useful on its own, but using their pre-built components sped up the development especially without a designer.
Embeddings
One of the key features of CreateTable is its built-in matching for columns. It uses several strategies. The first and the simplest being an exact string match. It also reuses previously defined matches that were manually picked for a previous file if the source and destination schemas are the same. But the most automatic and powerful is the embeddings based matching.
For our purpose here, an embedding is a vector of floats that represents a string (it’s a more expansive topic than that, but this is the part we care about). Using embeddings from multiple strings, we can compare the similarity of the vectors. This is the backbone of LLMs. For CreateTable we have a cache of embeddings for all the common column names that are used (sourced from 10s of thousands of public csvs). When generating a mapping between columns we can use those embeddings to find the closest match to the destination schema’s column name.
Depending on how the embedding are created, the can do more than just match similar strings, they can match similar meanings. For example, “zip” and “postal code” are different strings, but they are similar in meaning and should be matched. Even across languages, embeddings can be used to match similar meanings for example “name” and “nombre” are similar in meaning and should be matched.
The embeddings that are used on createtable.io are from OpenAI’s embedding API. and the process to generate, store and retrieve had inspiration from Simon Willison’s openai-to-sqlite which is talked about in more detail in the post Storing and serving related documents with openai-to-sqlite and embeddings
Validation
Of course just because the column names are all aligned doesn’t mean the data in column conforms to the required format. Validations can be added per column, and are run after the column matching has been done. The validations are run over the whole imported dataset and can then be reviewed. A validation can configured to reject the whole file, skip the row, or just nullify the invalid cell value.
Try it out today
CreateTable.io is live to try out. It is early access beta, but I’m looking for feedback and to see how people are using it. If you are interested in trying out self hosting, please reach out to me and I can help you get started. mick@createtable.io
A more complete guide about CreateTable is available in the docs.
Future
Based on feedback and interest we will see what features to add next. Some ideas:
- Write directly to datastores, currently you can export final data to a number of formats.
- More advanced and reusable transformations. I don’t think CreateTable should be a data editing tool like Excel, but applying transformations across a whole dataset can be useful.
- Full automation. If it doesn’t flag any validation errors, it should be able to be run automatically on new files.
- An embeddable data import UI. Currently CreateTable is meant for internal use, but a simplified UI that can be embedded in a customer facing application would open new possibilities.